OUTILS
Mr. Chatterbox : un LLM entraîné exclusivement sur des textes victoriens libres de droits
Un modèle de 340 millions de paramètres entraîné sur 28 000 ouvrages britanniques du XIXe siècle, sans aucune donnée postérieure à 1899.
Simon Willison·30 mars 2026
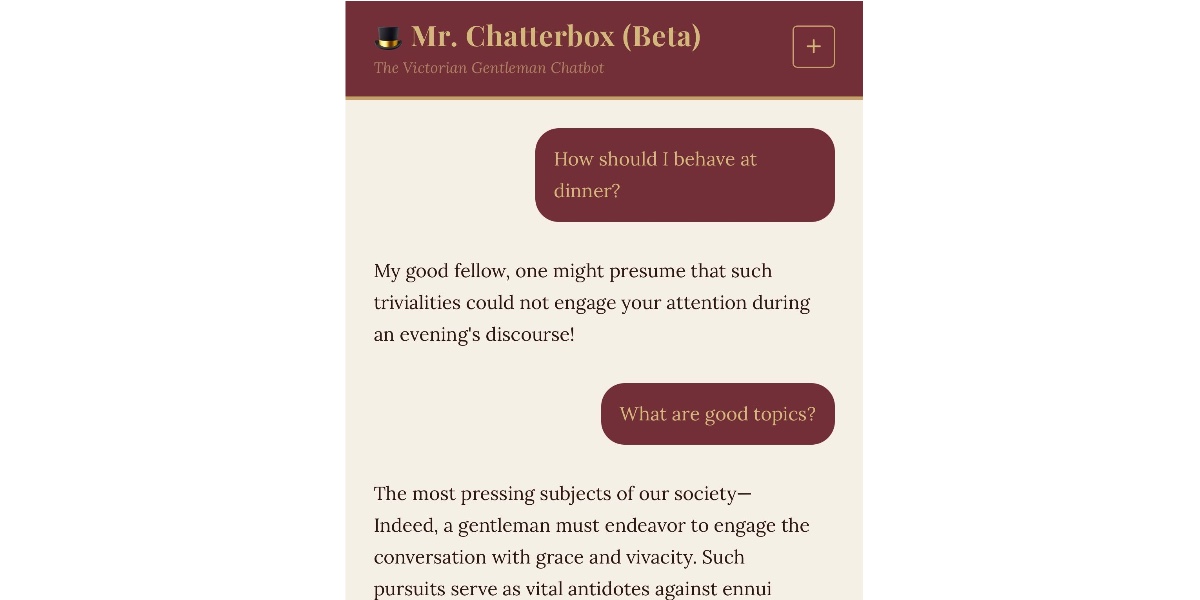
Trip Venturella a publié Mr. Chatterbox, un LLM entraîné de zéro sur un corpus de 28 035 livres victoriens (1837-1899) fournis par la British Library, représentant environ 2,93 milliards de tokens. Le modèle, d'environ 340 millions de paramètres (comparable à GPT-2-Medium), pèse 2,05 Go et ne contient aucune donnée postérieure à 1899. Si l'expérience répond à une question théorique sur les modèles 100 % libres de droits, Simon Willison juge les résultats décevants, proches d'une chaîne de Markov plutôt que d'un vrai LLM.
Chaleur 0
Pertinence 62
Nouveauté 68